Back in the late 2000's, I took the terrifying step of creating folders on my computer to start pursing my formal dissertation research. Around the same time, I realized that my system for organizing my paper files had become a sandbag. The physical compartments I was using to segregate "different" aspects of my work were hurting my ability to see and explore the overlapping areas of several inter-connected problems. I tore everything apart and put it back together again so the overall structure was different, the grains of information were different, and the "bins" were collapsed into a single well that I could draw from. In order to stop blindly analyzing the different parts of the elephant and start trying to understand the whole animal, you first have to understand that you're looking at pieces of a much larger puzzle.
It was more of a strategy than an epiphany.
Last week I got into the nitty-gritty of a SEAC paper I'm writing with David G. Anderson (University of Tennessee). We're using various large datasets to try to describe and interpret patterns of change in archaeological remains that could be related to changes in the size, structure, and distribution of human populations in the Eastern Woodland during the Late Pleistocene and Early Holocene.
As I started pulling together information (from PIDBA, DINAA, and my ongoing radiocarbon compilation) and thinking about how to organize it, I realized that keeping the databases separate was both a logistical hassle and an analytical problem. I invested in dumping all the information into a single relational database that we can use for this paper and that I'll continue to update in the future. I've been calling it "Megabase" in my head. So that's what it is until it gets a better name.
Here is an illustration that I'll briefly discuss:
It was more of a strategy than an epiphany.
Last week I got into the nitty-gritty of a SEAC paper I'm writing with David G. Anderson (University of Tennessee). We're using various large datasets to try to describe and interpret patterns of change in archaeological remains that could be related to changes in the size, structure, and distribution of human populations in the Eastern Woodland during the Late Pleistocene and Early Holocene.
As I started pulling together information (from PIDBA, DINAA, and my ongoing radiocarbon compilation) and thinking about how to organize it, I realized that keeping the databases separate was both a logistical hassle and an analytical problem. I invested in dumping all the information into a single relational database that we can use for this paper and that I'll continue to update in the future. I've been calling it "Megabase" in my head. So that's what it is until it gets a better name.
Here is an illustration that I'll briefly discuss:
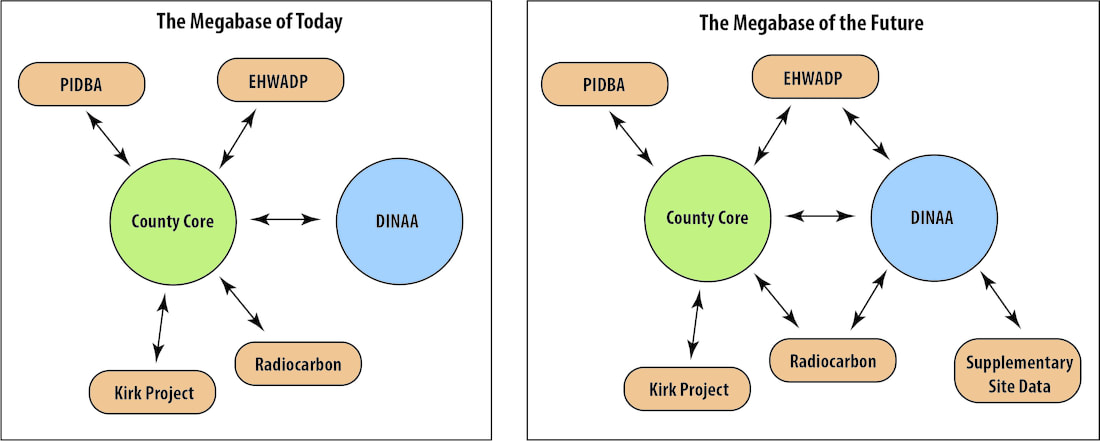
- DINAA is a compilation of state-curated site data, one entry per Smithsonian Trinomial;
- PIDBA has county-by-county counts of various kinds of Paleoindian projectile points;
- EWHADP is a compilation of prehistoric structure data (keyed to both county and Smithsonian Trinomial);
- The Kirk Project is point-by-point attribute data, with most entries having county-level provenience;
- Most of the entries in the radiocarbon compilation have a Smithsonian Trinomial.
On the left is what I'm building now. I used GIS to generate a listing of "center" UTM coordinates (n=2097) for every county in the eastern US (everything east of the first tier of states west of the Mississippi River) and much of eastern Canada. I'm calling that the "County Core." That coordinate list lets me easily create a spatially-reference file for whatever other information I want from any of the other databases without needing to know the exact locations of archaeological sites. Making a county-level map of all eastern radiocarbon dates in the database (9,533 and counting) in the eastern US is just a matter of a few button clicks in Access, Excel, and GIS. The same is true of the PIDBA data, the Kirk Project data, the household archaeology data, and the DINAA data.
The Megabase of Today will be fine for the SEAC paper and for the near future. It will be able to do a lot. Ideally, however, the Megabase of the Future will have DINAA serving as both a "router" for data that is attached to a Smithsonian Trinomial and an analytical tool in its own right. One issue is that not all states are currently participating (and therefore not all Smithsonian Trinomials -- the "addresses" for sites -- are in the system). Another issue is that the site forms (and therefore the site information that is collected and stored) differ by state. To reach its full potential, DINAA data will have to be supplemented by additional data about the materials recovered from sites, how sites were recorded, etc. Ensuring that we're making "apples to apples" comparisons will be a significant chore -- DINAA currently has information on somewhere in the neighborhood of half a million sites. You can't just sit on your couch and cross-check all that.
I know enough to be dangerous with a computer, but I'm not sufficiently sophisticated to know the nuts-and-bolts options for building the Megabase of the Future. In 2015 we did a sort of "proof" of concept to demonstrate that the EWHADP and DINAA could be linked together. I'm not sure if that is they way to go or not. Perhaps there's something that can be done with blockchain technology -- it sure sounds cool.
Anyway, I'm going to get the Megabase of Today functional in time to do the analysis for the SEAC paper we'll give in a month. If you're interested in talking about the Megabase of the Future, please let me know.
The Megabase of Today will be fine for the SEAC paper and for the near future. It will be able to do a lot. Ideally, however, the Megabase of the Future will have DINAA serving as both a "router" for data that is attached to a Smithsonian Trinomial and an analytical tool in its own right. One issue is that not all states are currently participating (and therefore not all Smithsonian Trinomials -- the "addresses" for sites -- are in the system). Another issue is that the site forms (and therefore the site information that is collected and stored) differ by state. To reach its full potential, DINAA data will have to be supplemented by additional data about the materials recovered from sites, how sites were recorded, etc. Ensuring that we're making "apples to apples" comparisons will be a significant chore -- DINAA currently has information on somewhere in the neighborhood of half a million sites. You can't just sit on your couch and cross-check all that.
I know enough to be dangerous with a computer, but I'm not sufficiently sophisticated to know the nuts-and-bolts options for building the Megabase of the Future. In 2015 we did a sort of "proof" of concept to demonstrate that the EWHADP and DINAA could be linked together. I'm not sure if that is they way to go or not. Perhaps there's something that can be done with blockchain technology -- it sure sounds cool.
Anyway, I'm going to get the Megabase of Today functional in time to do the analysis for the SEAC paper we'll give in a month. If you're interested in talking about the Megabase of the Future, please let me know.


 RSS Feed
RSS Feed
